I want to share a project I’ve been working on for the past few weeks!
Here at Proko Studio, we make educational art videos. We have an ever growing backlog of unedited videos because we film faster than we can edit..
With the crazy improvement to LLMs (things like ChatGPT) lately, I decided to attempt automated video editing. Most of our videos are dialogue heavy, so a large portion of the initial stages of editing can be automated with the power of GPT-4 and some process driven systems.
I made a tool that transcribes the audio, removes silence and “bad” dialogue, detects motion in drawing camera footage or screen captures, and creates a new sequence with everything clipped and organized in the timeline.
Initial tests show an 89% match with human decisions. That’s pretty wild!
While there are limitations and areas for improvement, it has already proven to be valuable at Proko Studio, improving efficiency and allowing the team to focus more on the creative stages of editing rather than the tedious. It allows us to jump into a project with more energy and a fresh mind to focus on the important details. Overall this leads to better videos, faster..
By the way, I am not a professional programmer. I’ve been using ChatGPT to teach me python, write initial versions of functions and help me improve my code! I’ve attempted to learn to code several times in my life, but never able to go beyond making websites. It’s ironic that a tool that can code for you also makes you better at doing it yourself.
Alright let’s get into the details.
What? How?
To start, we sync all the media using PluralEyes, and get an XML file which has the timing of all the media synced up. Thanks PluralEyes!
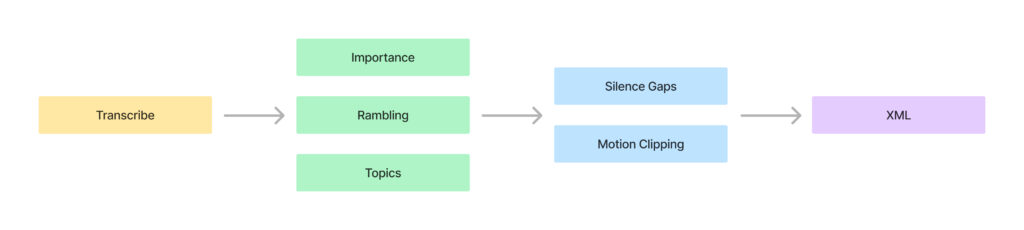
Transcription
The audio is sent through OpenAI’s Whisper for transcription. I favor the local version of Whisper over its API option for several reasons.. Word-based timecodes, customization options, support for larger file sizes, lower costs, and potential for future upgrades like speaker diarization (who’s talking).
Importance and Rambling
Once we have each sentence and timecodes, groups of 100 sentences are sent to GPT-4 to rate each sentence’s importance based on clarity and relevance. Another iteration identifies rambling and redundancy. Overall the robo-editor is instructed to think about the narrative and make it clear, engaging, entertaining, focused, cohesive, well paced, and keep moments that showcase the speaker’s personality or unique perspective.
Topics
And another iteration of GPT-4 with the remaining sentences to identify topic changes which gives us a quick overview of the video when we jump in to continue the editing. We can also use them for chapter breaks when publishing the video.
Ideal Silence Gaps
Then we get into some non-AI stuff to automate some more tedious stuff. First it refines the timecodes of the sentences by analyzing the audio file and finding the exact frame when each sentence starts and ends (the transcription is usually off a little). From there it adds ideal silence gaps between sentences based on the pacing of the dialogue.
Motion Clipping
We usually have drawing footage.. Either a screen recording for digital art, or an overhead camera recording for traditional. It detects the type of footage and then identifies areas with motion based on pixel change data, again applying padding and minimum clip size and gap size.
Final Sequence
At this point it has all the info it needs to create an XML file that we import into Premiere. It clips the face cam, audio, and the drawing footage and ripple deletes all the gaps.
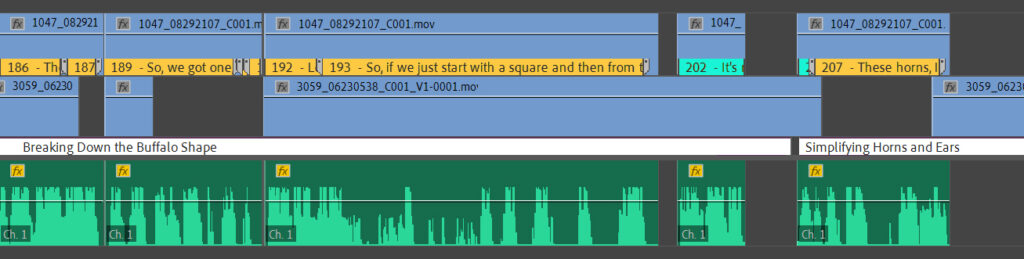
Here’s a closeup where you can see the topic title, and sentence markers with the text and rating colors. This is where the human editor takes over to finalize the video by adding sound effects, visual callouts, camera choices, jokes, etc..
Results
In initial tests, I measured performance by comparing its decisions with those made by a human editor. The results show a high degree of agreement.
In a video with 22 minutes of dialogue:
- True Positives: 14.1m (the system correctly identified sentences to keep)
- True Negatives: 6.0m (the system correctly identified sentences to cut)
- False Positives: 1.4m (the system kept sentences the human editor would have cut)
- False Negatives: 0.5m (the system cut sentences the human editor would have kept)
And some performance indicators:
- Accuracy: 91.1%
- Balanced Accuracy: 88.5%
- True Positive Rate: 96.4%
- True Negative Rate: 80.7%
And an overall 89% SUPER SCORE – a score I completely made up!
That’s an 89% match with human decision of what sentences to keep and cut, using zero-shot prompting. WTF. There’s also a notably low rate of false negatives, suggesting that the chop-bot errs on the side of inclusion, making sure it doesn’t chop out the good stuff.
The false positive rate though.. I’ll need to play with it to make it more aggressive and hopefully align even more. Also, while it performed exceptionally in our specific use-case at Proko Studio, the performance may vary with different types of content. It’s currently best for videos that have one primary speaker and are structured primarily based on the dialogue. When the timing of the video is heavily dependent on visuals or reorganization of the dialogue, it flops. That being said, even in such cases, the clipped dialogue significantly helps us speed up the boring portion of the workflow.
What’s next?
Moving forward, I plan to:
- Improve Prompting – Try the latest research on “Chain of Thought” and “Tree of Thoughts” prompting methods. These methods could potentially improve its ability to follow complex narrative threads to make better decisions on sentence importance.
- New Models – Test the performance of OpenAI’s increased context limit with their recent launch of the GPT-4-32k-0613 model. When the model can see a larger portion of the transcript at a time, it could potentially make better decisions. Maybe?
- Speaker Diarization – Detect who is speaking and add speaker labels to better handle videos with multiple speakers, such as interviews and podcasts.
- Camera Selection – Along with speaker diarization would come multiple speaker camera selection. We can also implement eye tracking to detect when the speaker is making eye contact with the camera and decide when to show the face cam or drawing footage.
- Auto translation and dubbing to common languages
- Transitions, effects, media suggestions.
Reach out to me if you have any questions, suggestions, or opportunities for collaboration.
Here is one of the first videos from Proko Studio utilizing Dr. Slicer. There is still quite a bit of human touch in this (thank you Hannah Lim), but the base was made by our Auto Editor in about 30 minutes.